机器学习、人工智能、深度学习是什么关系?
1956 年提出 AI 概念,短短 3 年后(1959),Arthur Samuel 提出机器学习概念:
Field of study that gives computers the ability to learn without being explicitly programmed.
机器学习不是某一具体算法,而是许多算法的统称。深度学习是机器学习的一种,其他常见方法包括决策树、聚类、贝叶斯等。深度学习灵感来自大脑神经元互连,人工神经网络(ANN)即模拟大脑生物结构的算法。
人工智能(AI)包含机器学习(ML),而机器学习包含深度学习(DL),三者关系如下:

面向所有人的机器学习科普大全
什么是机器学习?
机器学习的核心思路是通过算法让计算机从数据中学习并进行预测,而非人工编写规则。理解其本质,有助于更好地应用于工作与生活中。
机器学习的基本思路
机器学习的三步核心流程:
- 将现实问题抽象为数学模型,并明确参数含义;
- 利用数学方法求解模型,解决实际问题;
- 评估模型效果,判断其是否真正解决问题及效果如何。
不是所有问题都可转化为数学模型,只有可数学化的问题才能由 AI 解决。

机器学习的原理
以监督学习为例,类比人类识字过程:
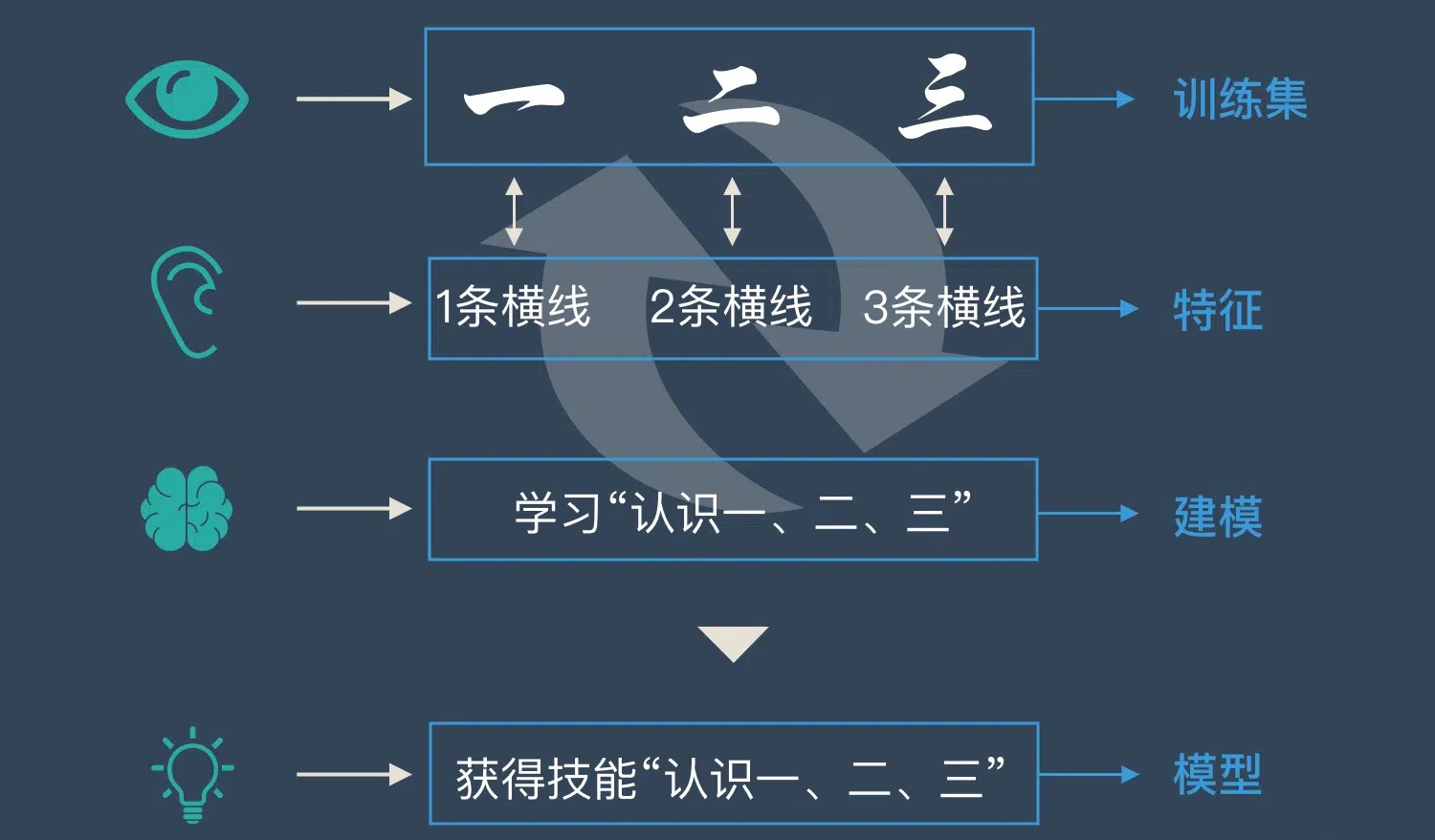
我们展示写有“一、二、三”的卡片,让小朋友学习识别,反复训练后,小朋友学会识字。
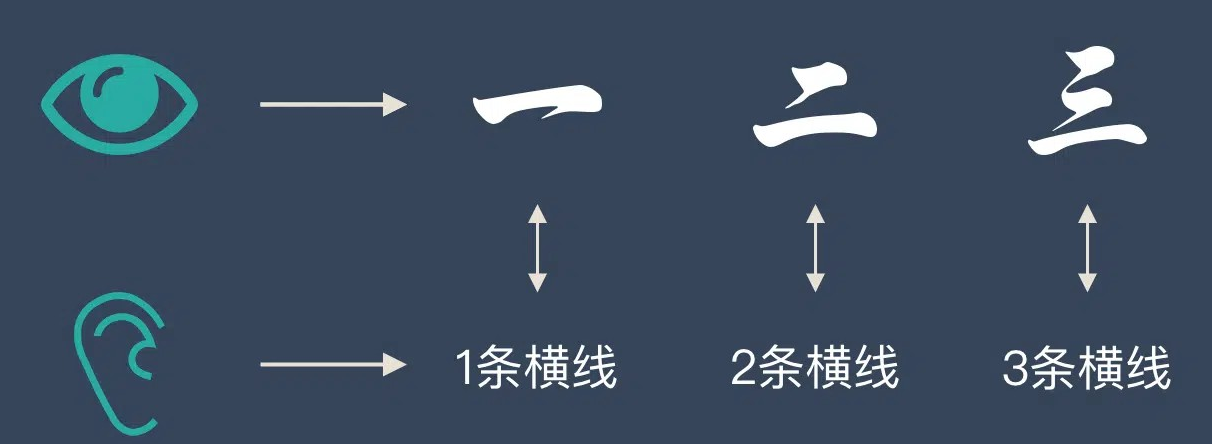
在机器学习中:
- 训练集:识字卡片;
- 特征:卡片上横线条数;
- 建模:反复学习过程;
- 模型:学会识字后总结的规律。
整个过程即“机器学习”。
监督学习、非监督学习、强化学习
监督学习
在训练集中,所有样本都有正确标签。机器通过学习标签数据,掌握预测方法。
示例:给猫狗照片打标签,训练后可识别新照片中的猫或狗。
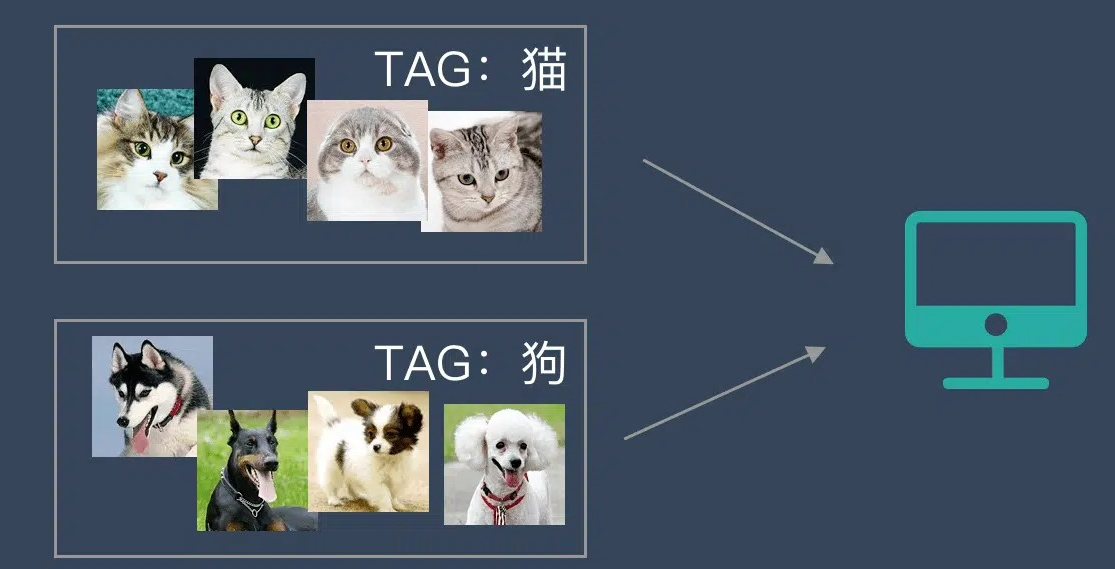
【当机器遇到新的小狗照片时就能认出它】

这种通过大量人工打标签来帮助机器学习的方式就是监督学习。这种学习方式效果非常好,但是成本也非常高。
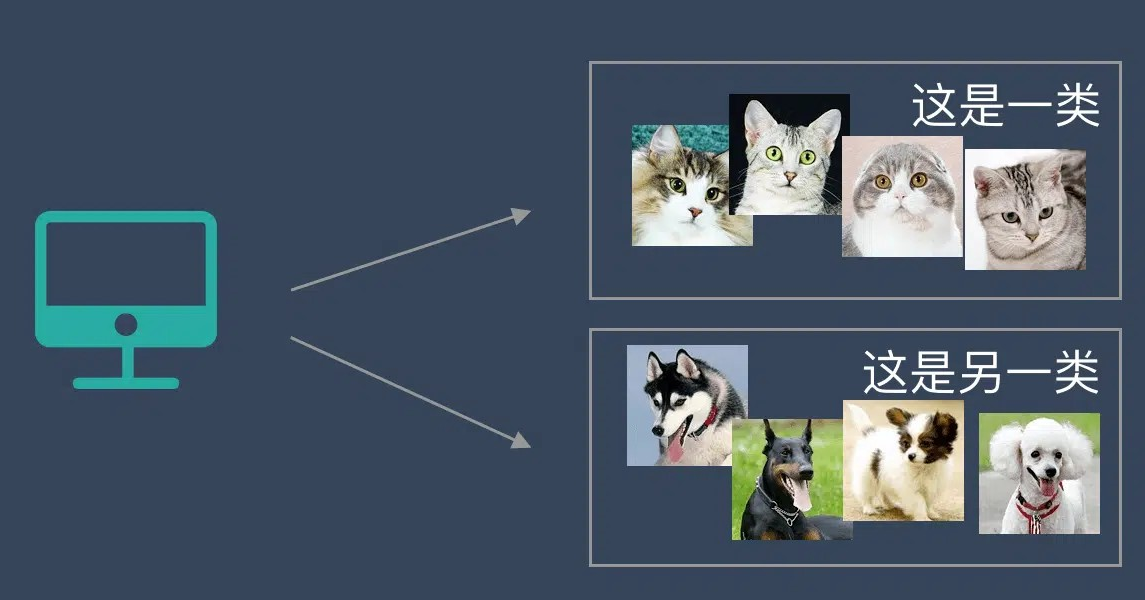
非监督学习
训练集中无标签,机器需从数据中挖掘潜在结构。
示例:将未标注的猫狗照片聚类成两类,但机器并不知哪类为猫、哪类为狗。
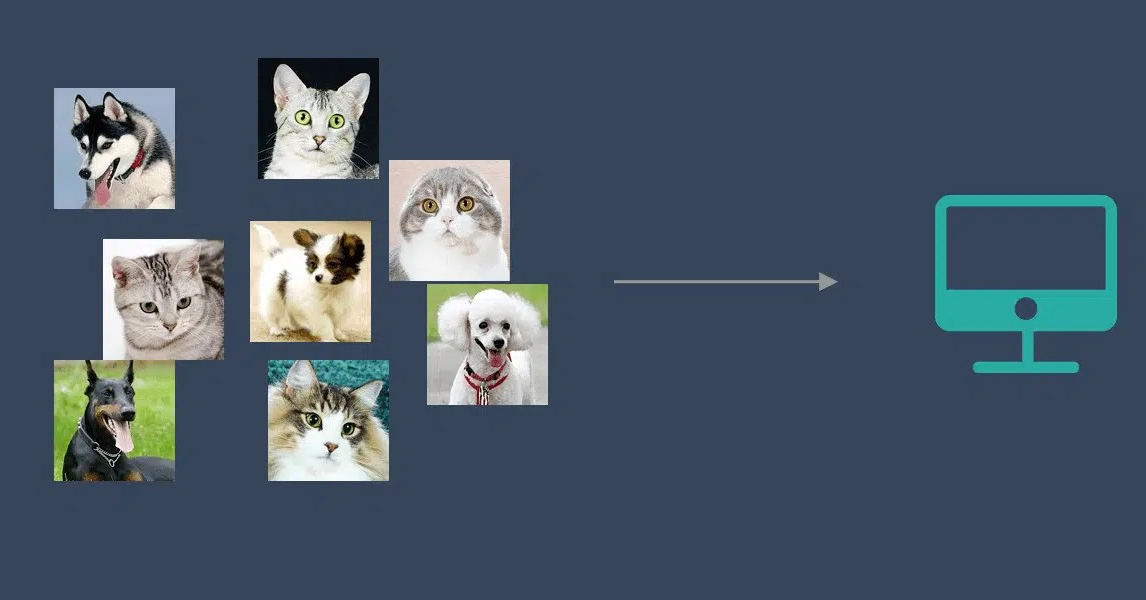
通过学习,机器会把这些照片分为2类,一类都是猫的照片,一类都是狗的照片。虽然跟上面的监督学习看上去结果差不多,但是有着本质的差别:
非监督学习中,虽然照片分为了猫和狗,但是机器并不知道哪个是猫,哪个是狗。对于机器来说,相当于分成了 A、B 两类。
强化学习
智能体在环境中通过行为获得回报,以最大化累积回报为目标。
典型场景:游戏。2019 年,AlphaStar 完虐《星际争霸》职业选手 TLO 与 MANA。
【强化学习示例:AlphaStar】
机器学习实操的7个步骤
步骤1:收集数据
我们在超市买来一堆不同种类的啤酒和红酒,然后再买来测量颜色的光谱仪和用于测量酒精度的设备。
接下来,我们把每瓶酒都标记出它的颜色和酒精度,从而形成如下表格:
| 颜色 | 酒精度 | 种类 |
|---|---|---|
| 610 | 5 | 啤酒 |
| 599 | 13 | 红酒 |
| 693 | 14 | 红酒 |
| … | … | … |
这一阶段的关键是数据的 数量与质量,它们直接决定了后续模型的好坏。
步骤2:数据准备
在这个例子中,数据看似整洁,但现实中常需进行数据清洗、处理缺失值、异常值等操作。
当数据准备完成后,我们将其划分为:训练集(60%)、验证集(20%)、测试集(20%),用于模型训练、调优与评估。

数据准备还可包括标准化、归一化、数据增强等技巧,更多细节可参考《AI 数据集最常见的6大问题(附解决方案)》。
步骤3:选择一个模型
研究人员开发了各种模型,适用于不同数据类型:
- 图像数据 → 卷积神经网络(CNN)
- 序列数据 → 循环神经网络(RNN)
- 数字/表格数据 → 线性模型、决策树、随机森林等
在本示例中,我们只有两个特征(颜色、酒精度),可使用简单的线性模型进行预测。
步骤4:训练
训练阶段无需人工干预,机器通过算法自动学习模型参数,类似于“做算术题”。
虽然训练看似重要,但数据质量与模型选择往往比训练过程本身更为关键。
步骤5:评估
训练完成后,使用验证集和测试集评估模型性能。常见指标包括准确率(Accuracy)、召回率(Recall)、F1 值等。 这个过程就不需要人来参与的,机器独立就可以完成,整个过程就好像是在做算术题。因为机器学习的本质就是将问题转化为数学问题,然后解答数学题的过程。
评估结果反映了模型在未见数据上的表现,衡量其在真实场景中的可用性。
步骤6:参数调整
根据评估结果,对模型超参数进行调整(如学习率、正则化强度、树的深度等),以提升模型性能。
参数调整通常结合交叉验证或网格搜索等方法,反复试验找到最佳配置。
步骤7:预测
在前六步的基础上,使用最终模型对新数据进行预测。例如,当我们购买一瓶新酒,只需输入其颜色和酒精度,模型即可判断其是红酒还是啤酒。
示例案例:区分红酒与啤酒

YouTube 视频:《The 7 Steps of Machine Learning》(需科学上网)

15种经典机器学习算法
| 算法 | 训练方式 |
|---|---|
| 线性回归 | 监督学习 |
| 逻辑回归 | 监督学习 |
| 线性判别分析 | 监督学习 |
| 决策树 | 监督学习 |
| 朴素贝叶斯 | 监督学习 |
| K邻近 | 监督学习 |
| 学习向量量化 | 监督学习 |
| 支持向量机 | 监督学习 |
| 随机森林 | 监督学习 |
| AdaBoost | 监督学习 |
| 高斯混合模型 | 非监督学习 |
| 限制玻尔兹曼机 | 非监督学习 |
| K-means 聚类 | 非监督学习 |
| 最大期望算法 | 非监督学习 |
百度百科+维基百科
更多详情请参考百度百科和维基百科相关条目。
补充资料2:优质扩展阅读
详细了解机器学习,请参考文章《面向所有人的机器学习科普大全》。
发表评论